从 RAG 到代理 RAG 再到代理记忆的演变 The Evolution from RAG to Agentic RAG to Agent Memory[译文]
我一直在学习人工智能代理中的记忆,发现自己被所有的新术语淹没了。一开始是短期记忆和长期记忆。然后变得更加混乱,包括程序性记忆、情节记忆和语义记忆。但等等,语义记忆让我想起了一个熟悉的概念:检索增强生成(RAG)。
代理中的记忆是否是普通 RAG 演变为代理 RAG 后的下一步?代理中的记忆核心在于将信息转移进大型语言模型(LLM)的上下文窗口。无论你称这些信息为“记忆”还是“事实”,对这个抽象来说都是次要的。
这篇博客是从一个不同的角度介绍人工智能代理中的记忆,可能与其他博客中看到的不同。我们不会(还不)谈论短期记忆和长期记忆,而是逐渐将简单的 RAG 概念演变为代理 RAG,再到智能体中的记忆。(请注意,这是一个简化的模型。代理记忆的整个主题在底层更为复杂,涉及诸如记忆管理系统等内容。)
RAG:一次性只读
检索增强生成(RAG)的概念于 2020 年首次提出(Lewis 等人),并在 2023 年左右获得了广泛关注。这是第一个让无状态的 LLM 访问过去对话和在训练时未见过且未存储在其模型权重中的知识(参数知识)的概念。
简单 RAG 工作流程的核心思想很简单,如下图所示:
- 离线索引阶段:将额外信息存储在外部知识源(例如,向量数据库)中。
- 查询阶段:使用用户的查询从外部知识源中检索相关上下文。将检索到的上下文与用户prompt一起输入到 LLM,以获得基于额外信息的响应结果。

以下伪代码说明了简单的 RAG 工作流程:
1 | # Stage 1: Offline ingestion |
尽管简单的 RAG 方法在减少简单用例的幻觉方面是有效的,但它有一个关键的局限性:它是一个一次性解决方案。
- 额外信息通常是从外部知识源获取的,而不考虑其是否真的必要。
- 信息只被检索一次,无论检索到的信息是否相关或正确。
- 所有额外信息只有一个外部知识源。
这些限制意味着,对于更复杂的用例,如果检索到的上下文与用户查询无关甚至错误,LLM 仍然可能产生幻觉。
代理 RAG:通过工具调用只读
代理 RAG 解决了简单 RAG 的许多局限性:它将检索步骤定义为代理可以使用的工具。这个变化使得代理首先能够确定是否需要额外的信息,决定使用哪个工具进行检索(例如,具有专有数据的数据库与网络搜索),并评估检索到的信息是否与用户查询相关。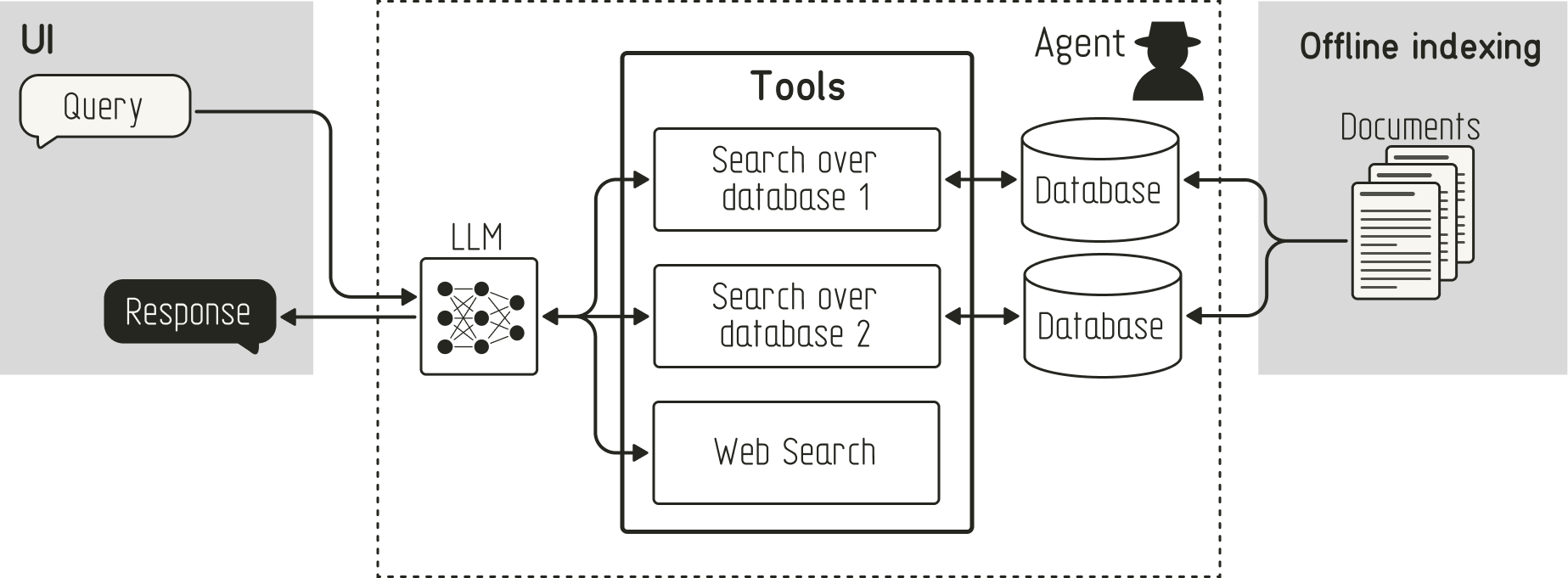
以下伪代码说明了代理如何在代理 RAG 工作流程中调用 SearchTool :
1 | class SearchTool: |
两者之间的一个相似之处是信息存储在离线数据库中,而不是在推理过程中。这意味着数据仅由代理检索,而不是在推理过程中被写入、修改或删除。这一限制意味着两种 RAG 系统都无法从过去的交互中学习和改进(默认情况下)。
代理记忆:通过工具调用进行读写
代理记忆通过引入记忆管理概念解决了 RAG 的这一限制。这使得代理能够从过去的交互中学习,并通过更个性化的方法增强用户体验。
代理记忆的概念建立在Agentic RAG 的基本原则之上。它还使用工具从外部知识库(记忆)中检索信息。但与Agentic RAG 不同,代理记忆还使用工具向外部知识库写入信息,如下所示: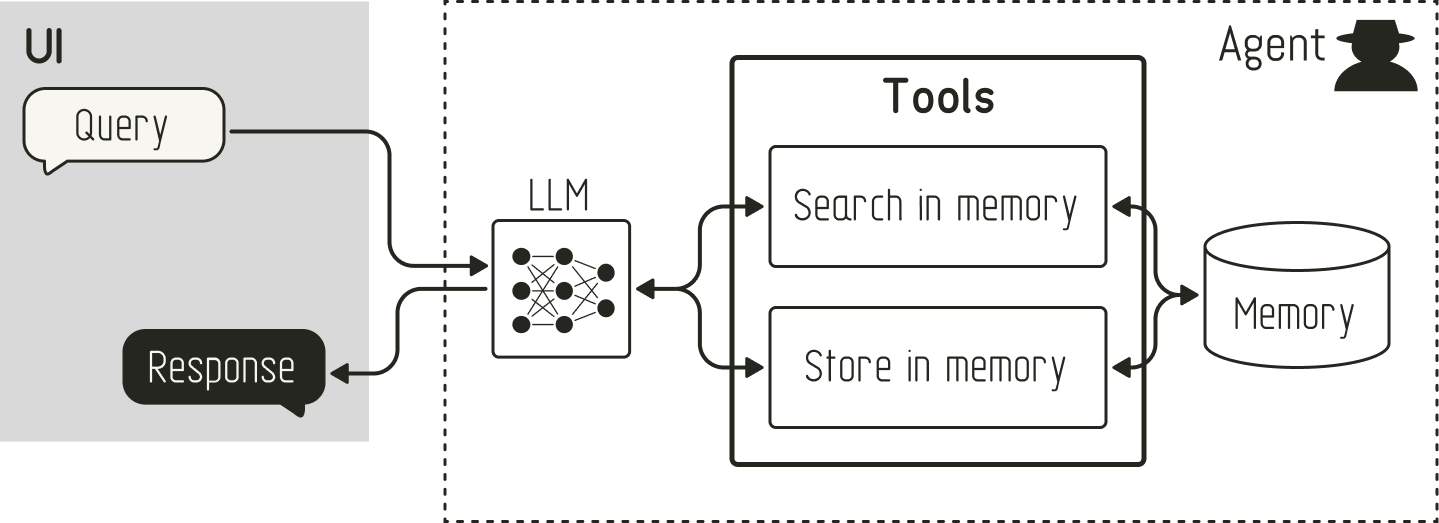
这使得代理不仅能够从记忆中回忆信息,还能够“记住”信息。在最简单的形式中,您可以在交互后将原始对话历史存储在一个集合中。然后,代理可以搜索过去的对话以找到相关信息。如果您想扩展这一点,可以提示记忆管理系统创建对话的摘要以供将来参考。此外,您还可以让代理在对话中注意重要信息(例如,用户提到对表情符号的偏好或提到他们的生日),并基于此事件创建记忆。
以下伪代码说明了代理记忆的概念如何扩展Agentic RAG 的想法,以及代理可以用来存储信息的 WriteTool :
1 | class SearchTool: |
这个简化模型的局限性
正如本博客开头所述,这种对 AI 代理中记忆的比较只是一个简化的模型。它帮助我将其置于我已经熟悉的事物的视角中。但为了避免让 AI 代理中的记忆主题看起来仅仅是带有写操作的代理 RAG 的扩展,我想强调这种简化的一些局限性:
上面的 AI 代理记忆插图为了清晰而进行了简化。它只显示了单一的记忆来源。然而,在实践中,您可以使用多个来源来处理不同类型的记忆:您可以为
- “程序性”记忆(例如,“与用户互动时使用表情符号”),
- “情节性”记忆(例如,“用户谈论了在 10 月 30 日计划一次旅行”),以及
- “语义记忆”(例如,“埃菲尔铁塔高 330 米”),
如 CoALA 论文中所讨论的。此外,您可以为原始对话历史建立一个单独的数据集合。
上述示例的另一个简化是,它缺少除了 CRUD 操作之外的内存管理策略,如 MemGPT 中所见。
此外,尽管代理记忆实现了持久性,但它引入了 RAG 和Agentic RAG 所没有的新挑战:记忆损坏和需要记忆管理策略,例如遗忘。
总结
RAG、Agentic RAG 和代理记忆的核心在于如何创建、读取、更新和删除存储在外部知识源中的信息(例如,文本文件或数据库)。
| 存储信息 | 检索信息 | 编辑和删除信息 | |
|---|---|---|---|
| RAG | 离线检索阶段 | 一次性 | 手动 |
| Agentic RAG | 离线检索阶段 | 工具动态调用 | 手动 |
| Memory in Agents | 工具动态调用 | 工具动态调用 | 工具动态调用 |
最初,优化简单 RAG 的关键重点在于优化检索方面,例如,使用不同的检索技术,如向量检索、混合检索或基于关键词的搜索。然后,重点转向使用正确的工具从不同的知识源中检索信息(“我需要检索信息吗?如果需要,来自哪里?”)。在过去一年中,随着代理中记忆的出现,重点再次发生了变化。这一次,重点转向信息的管理:虽然 RAG 和Agentic RAG 在检索方面有很强的关注,但记忆则包含了在外部知识源中创建、修改和删除数据的过程。